redis 2 - 高性能
一、概述
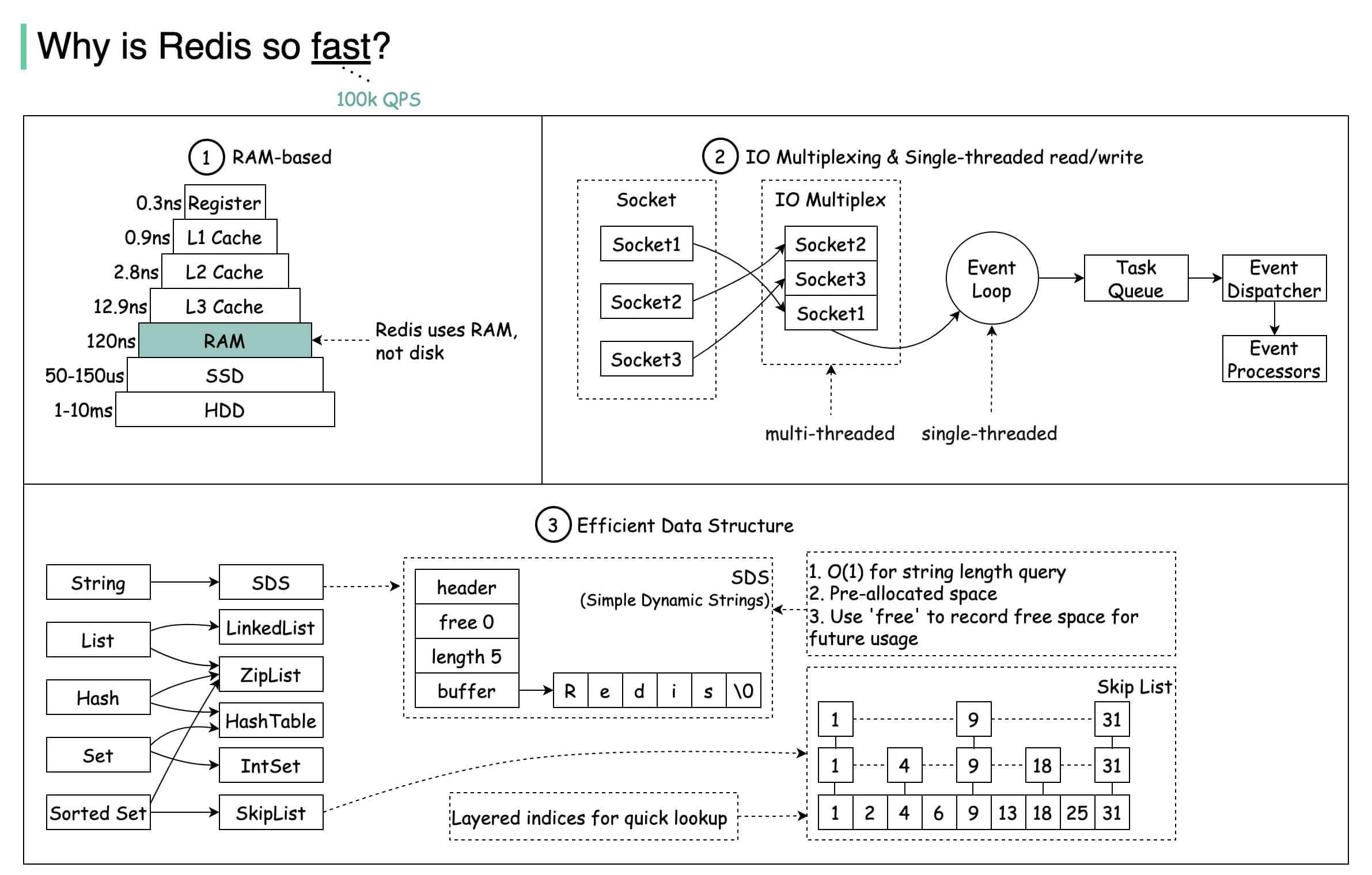
redis为什么快?
- 基于内存
- 基于Reactor模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和IO多路复用
- 高性能的数据结构实现
二、响应模型
IO多路复用
使用 I/O 多路复用技术来高效地管理多个网络连接。这允许 Redis 的单个线程非阻塞地处理多个客户端连接,接受请求并发送响应,而不是为每个连接分别阻塞等待。
事件驱动
- 事件处理:Redis 使用基于事件的模型来处理网络连接中的各种事件。当客户端发送请求到 Redis 服务器时,I/O 多路复用程序会监听到数据到达的事件,并通知 Redis 进行处理。
- 命令队列:到达的命令会被放入一个队列中,并由 Redis 的处理线程逐一执行。执行完成后,处理结果通过网络发送回客户端。
单线程处理
Redis 的大部分操作(包括命令处理、数据读写等)都在一个单线程中执行。这意味着在任意时刻,只有一个命令在被执行,从而避免了多线程环境中的上下文切换和锁竞争问题,确保了高效的命令执行。
部分异步操作
对于某些可能阻塞主线程的操作(如磁盘 I/O 操作),Redis 会采用异步方式处理,如使用后台线程进行 RDB 快照的持久化和 AOF 文件的重写。
Q:为什么使用单线程是个优势?
A:对于Redis来说,CPU本身不是瓶颈,不需要通过多线程的方式提升CPU的使用率。这样单线程模型也更简单。
Q:redis6.0引入了多线程?
A:多线程引入用于处理网络IO,核心逻辑执行还是在单线程中,并且多线程默认不开启,需要手动开启。
三、数据结构
Redis提供了丰富的数据类型,常见的有五种:String, Hash, List, Set, Zset
随着版本更新,支持了更复杂的数据类型: BitMap, HyperLogLog, Geo, Stream
数据类型是接口,面向用户的使用。底层实现是基于一些数据结构。
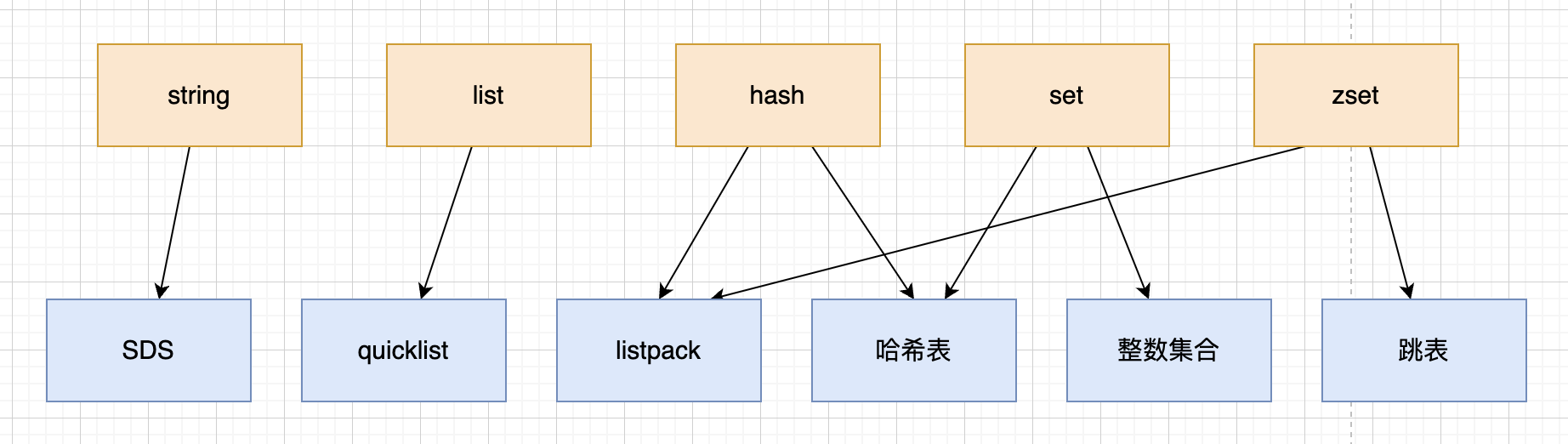

数据结构详情
SDS
1 | |
Redis默认的字符串表示被称为 简单动态字符串(SDS)
SDS和C字符串的区别
O1获得字符串长度
杜绝缓冲区溢出
比如在执行字符串连接的时候,C很容易缓冲区溢出,修改到其他内存
减少修改字符串时带来的内存重分配次数
Redis这种数据库,对速度要求严苛,数据会被频繁修改,不能接受每次修改数据库的长度都需要执行一次内存重分配
通过未使用空间解除字符串长度和底层数组长度之间的关联
SDS实现了空间预分配和惰性空间释放两种策略
空间预分配
用户优化SDS的字符串增长操作:当SDS的API对一个SDS进行修改,并且需要对SDS进行空间扩展的时候,不仅会为SDS分配修改必要的空间,还会分配额外的未使用空间
未使用空间数量由以下公式决定:
如果len<1MB 则分配同样大小的空间给free
如果len > 1MB 则分配1MB给free
惰性空间优化
用于优化字符串缩短操作:缩短操作时,不重新分配以释放该部分内存,存在free里。当有需要时,也可以通过API释放free空间
二进制安全
Redis使用len来判断字符串的结尾处,而不是’/0’,就可以存一些特殊数据格式
兼容部分C字符串函数
string的内部实现有两种,int或SDS
它的编码方式有三种,int(可以用long类型表示的整数)、raw、embstr.
其中后两种Redis会根据需要保存字符串的长度来决定,底层实现都是SDS。
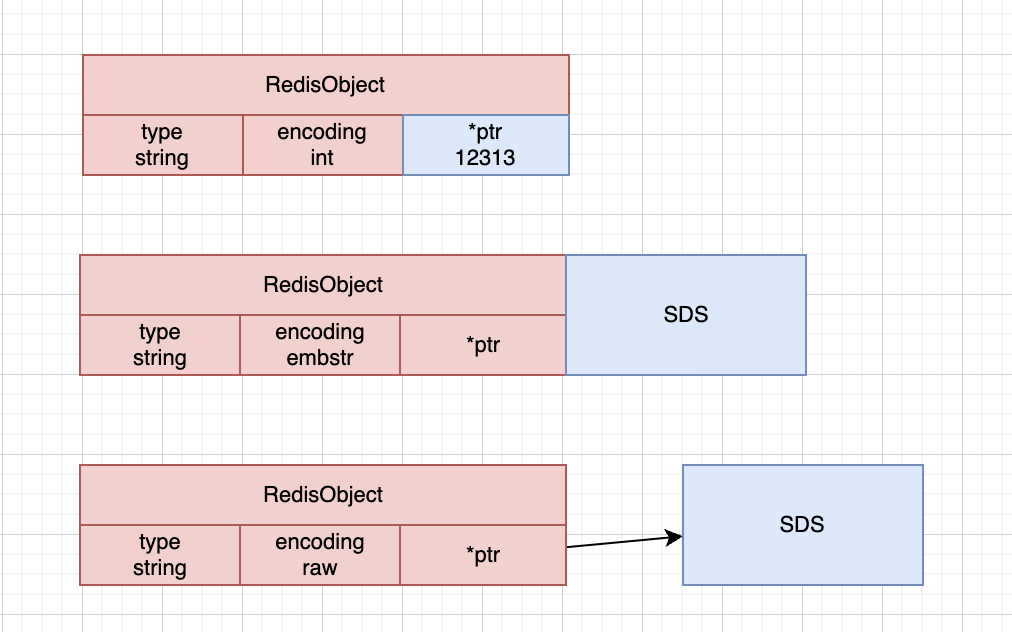
编码为int的string对象,会把值放在ptr里。
编码为embstr的string对象,会和SDS一起分配一块连续的内存。
编码为raw的string对象,会和SDS分配不连续的内存。
embstr这种编码方式,在内存分配、对象访问和内存释放时,都只需要请求一次。提升了对短字符串常量的创建、访问、销毁效率。
当int被修改为字符串时,会转换成raw;
当embstr被修改时,会转换成raw.(embstr是只读的)
跳表
链表的增删改查 核心都是需要定位到目标节点,普通链表只能通过遍历的方式,时间复杂度为O(n)
为了快速访问,可以增加多级索引。以这种思路,就产生了跳表。
通过建立多级索引,将查找的时间复杂度降低到O(logn)
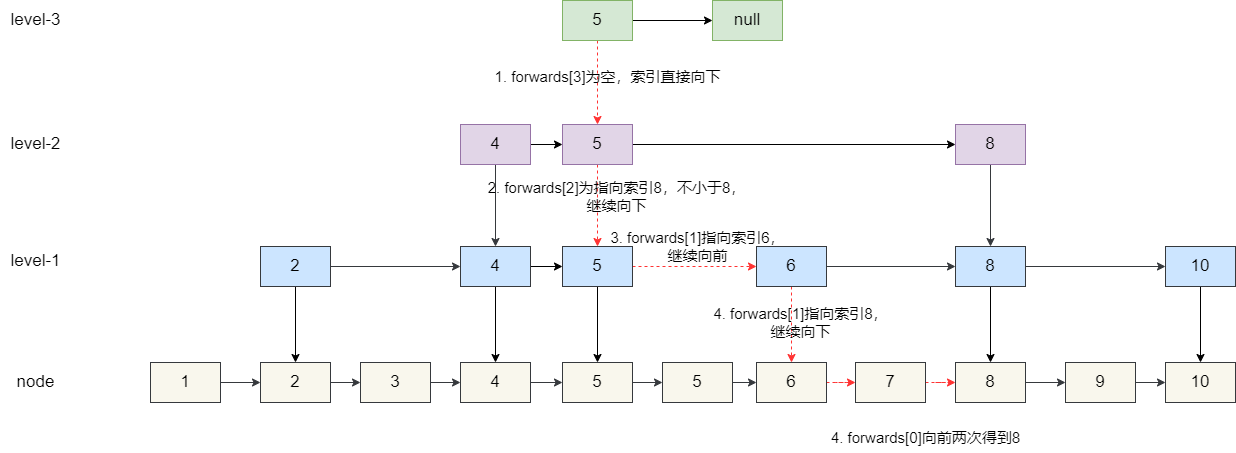
跳表和其他数据结构的对比
- 二叉平衡树:跳表追求概率平衡,而不是严格平衡。二叉平衡树相比于跳表,每次增删都需要旋转节点,逻辑复杂,速度慢。
- 红黑树:相比二叉平衡树,性能更高些,但是逻辑复杂,按照区间来查找数据也不如跳表。
- B+树:B+树核心思想是通过尽可能少的IO来定位到数据,因此层高不能很高,并且需要做节点分裂和合并。跳表的应用场景不需要这些。